
从「有规则不会配」到一份能用 YAML:我做 Clash YAML Builder 的过程
这个工具能帮你干啥
一句话:
你不用自己啃那种全是英文、缩进还不能错的配置文件;像做问卷一样点几步,最后给你一份能直接导入 OpenClash、Mihomo、Sparkle 的成品yaml配置文件,可以直接导入使用。
换成生活比喻:
你告诉店家「我要吃什么菜」(哪些网站、哪些 App 要走代理)、「送走菜路线」(走香港还是日本节点)、「食材从哪来」(机场订阅链接),店家帮你打包成一张「配送单」——在这里就是一份 YAML。
你实际只要在脑子里记住四件事:
我用啥设备上的代理? 路由器还是电脑、用哪家客户端,开头选一下。
我的节点从哪来? 把机场给的订阅链接贴上,工具会把节点收进来。
地区怎么分队? 比如「日本」「香港」各自一组;可以手写过滤条件,也可以用「关键词包含/不包含」让工具帮你写规则。
上网流量怎么走? 先勾选别人整理好的「网站/App 清单」(也可以从全库里搜,比如游戏、流媒体),再指定:这条清单走「AI 组」「流媒体组」还是默认代理——也就是「谁先过站、最后走哪国节点」。
和「直接抄别人配置」有啥区别?
别人的文件里,组的名字、订阅的名字往往和你对不上,一导入就报错或根本跑不起来;这个工具是按 你的 订阅、你的 分组习惯生成,少了很多对表改名的麻烦
工具页面预览

一、为什么做这个项目
很多用代理的人听过 Clash、OpenClash、Mihomo、Sparkle,也囤过订阅链接和别人的「大全规则」。但现实往往是:
规则非常多,但和自己设备、自己的节点对不上——抄来的 YAML 里策略组名、规则集引用、订阅名全要手工改一圈。
YAML 对非开发者不友好:缩进错一格、引号少一个,客户端就报错;想加一条「某个进程走某组」,要先搞懂
PROCESS-NAME、RULE-SET、策略组嵌套。真正想表达的是业务意图:「这个 App 走日本节点」「国内地址直连」「流媒体单独一组」——而不是先成为「Clash 语法专家」。
所以我想把问题倒过来:先让用户用向导说清楚「怎么分流」,再由程序生成对应平台能吃的配置。项目定位就是:把「我想怎么分流」稳定地变成「OpenClash / Mihomo / Sparkle 能直接用的 YAML」,并对小白尽量向导化,对以后加平台尽量不推倒重来。
二、架构怎么想的(为什么要分层)
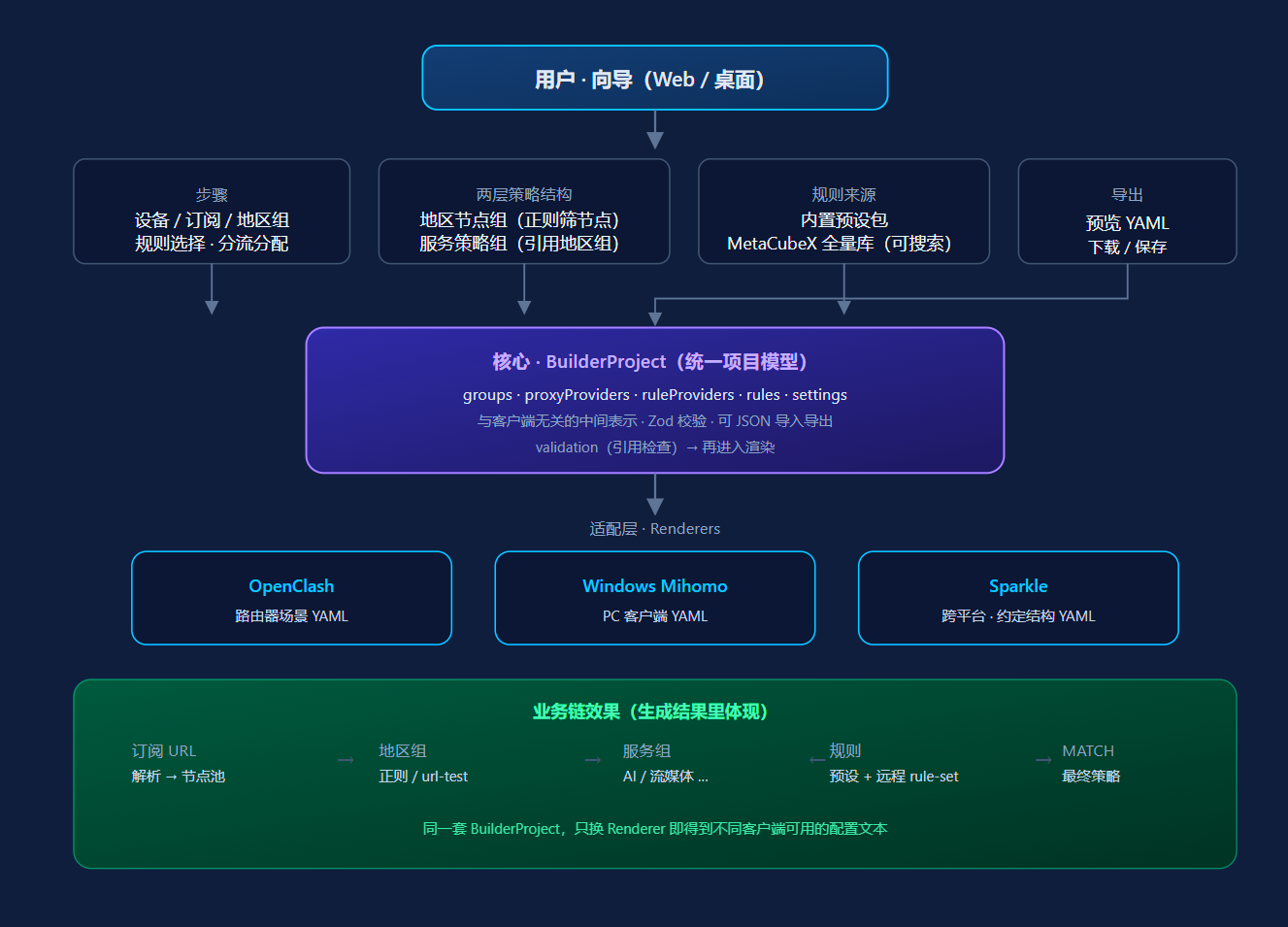
如果一开始就对着某一种客户端的 YAML 结构写界面,每多支持一个目标,多半就要复制粘贴一大套逻辑。更稳的做法是中间有一层与具体客户端无关的统一模型:
统一项目模型(BuilderProject)
存的是:策略组、节点/订阅来源、规则、开关项等「意图」,而不是某一版 Clash 的字段排列。适配层(Renderers)
OpenClash、Windows Mihomo、Sparkle 各自有约定和差异,只做一件事:把BuilderProject渲染成该目标下的 YAML(或约定结构)。以后加新客户端,主要加渲染器 + 能力表,而不是改整套向导。规则来源抽象
「规则从哪来」单独一层:内置快速模板、从 MetaCubeXmeta-rules-dat同步的全量 geosite/geoip 规则名等。UI 只负责「选规则、分配给哪个策略组」,不关心底层是内置包还是远程 rule-provider。导出与运行环境分离
网页里用浏览器下载;桌面(Tauri)里用系统保存对话框。同一套生成逻辑,换端只换「怎么把文件交给用户」。
这样分层的好处可以概括成三句话:加平台主要改适配层;加规则源主要改来源层;加分流场景主要改预设和分配——而不是每次需求变动都重写前端。
三、向导里用户实际在做什么(功能概览)
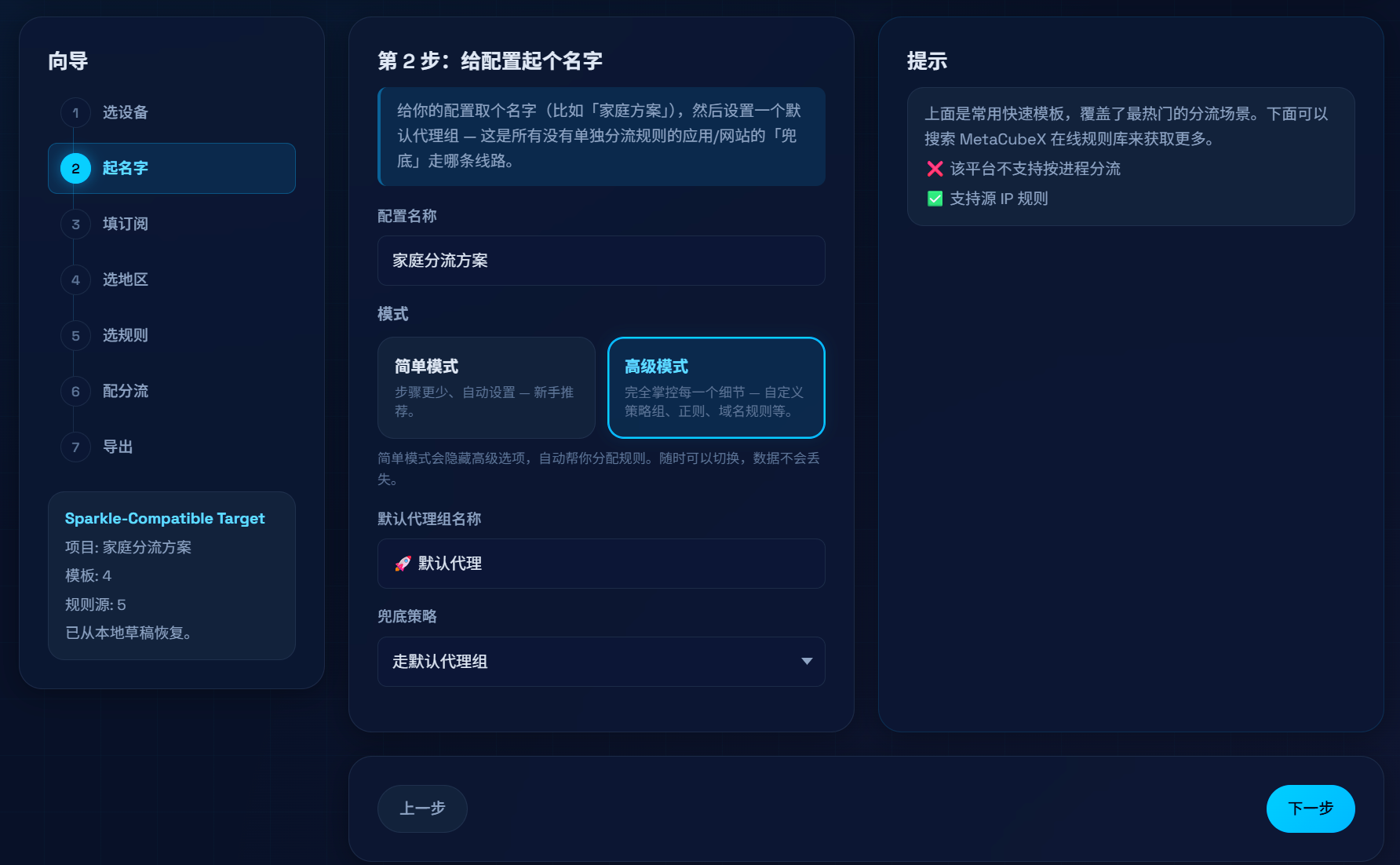
用一句话串起来:先选设备和模式 → 管订阅与地区节点组 → 选规则 → 把每条规则指到对应「服务策略组」→ 预览并导出 YAML。
更具体一点:
设备与模式
支持 OpenClash(路由)、Mihomo(Windows)、Sparkle(Windows / macOS / Linux)等目标;简单 / 高级模式可以少几步或全量控制。订阅
粘贴机场订阅链接,解析出的节点进入后续「地区节点组」的筛选逻辑,并写入生成结果(而不是只写一句proxy-provider让用户自己啃)。地区节点组
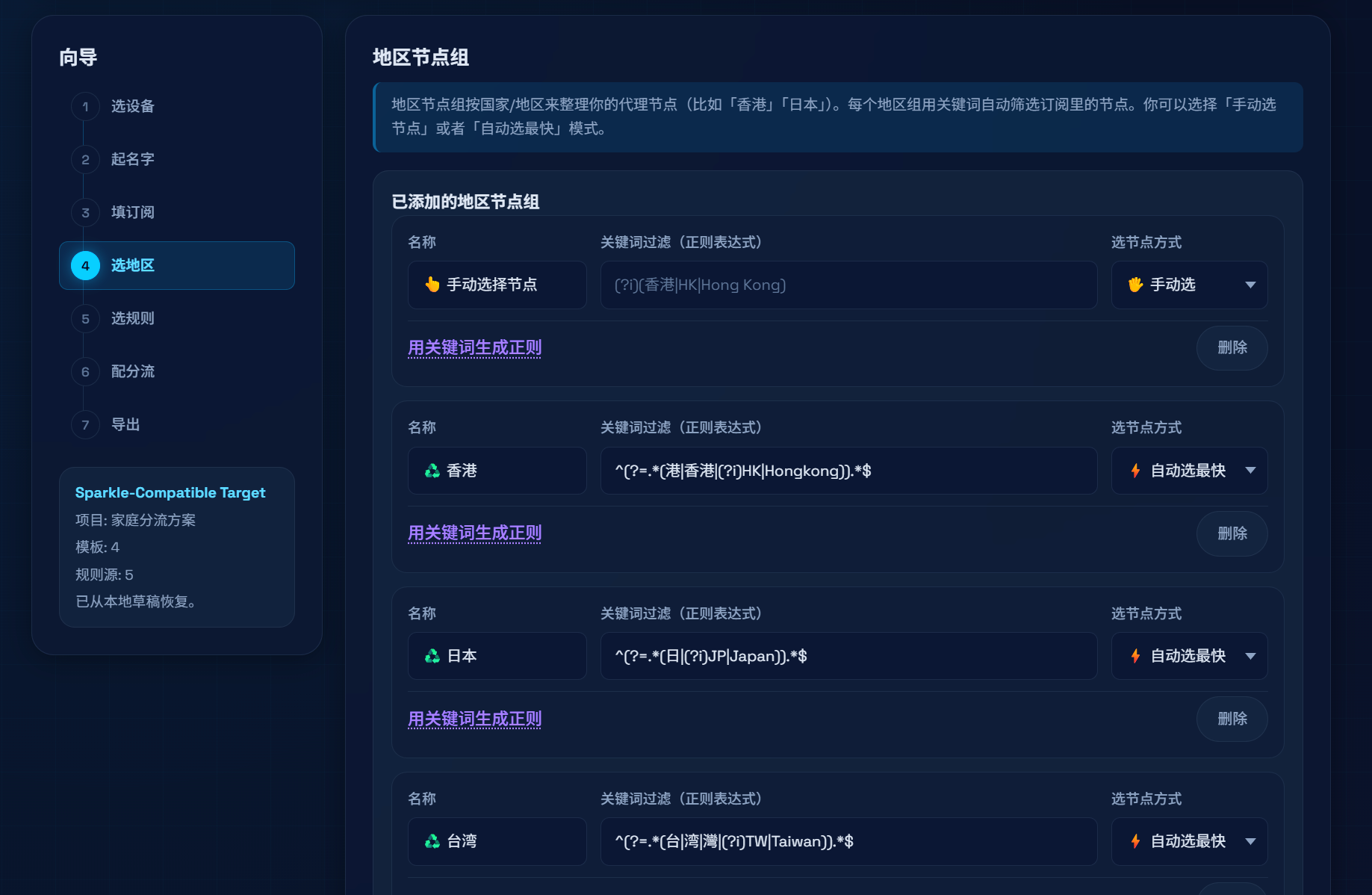
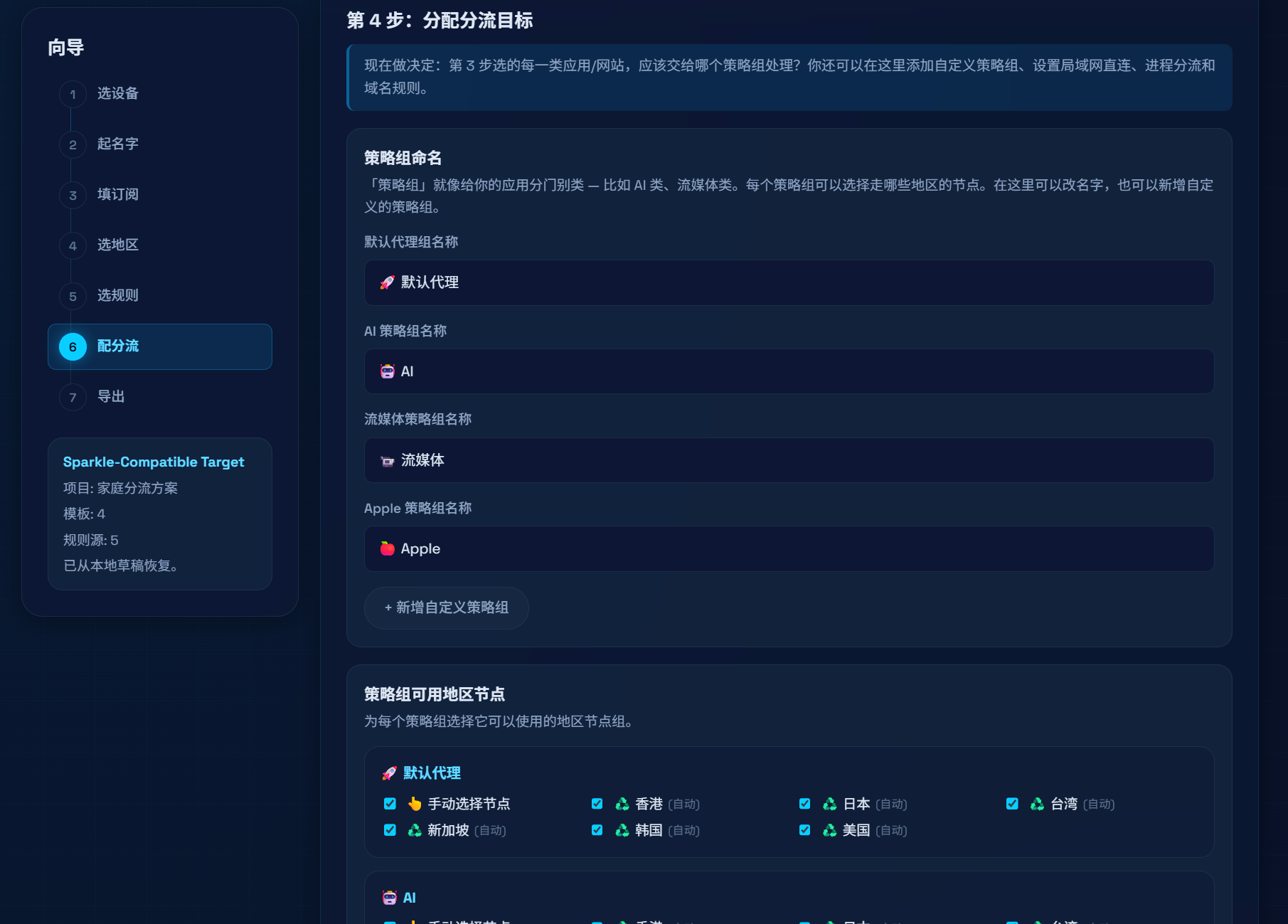
按国家/地区(或自定义名字)把节点归组,用正则筛节点名;可选手动选点或url-test自动测速。只有选了自动测速时才在展示名上带「自动」一类后缀,避免误导。服务策略组
「默认代理 / AI / 流媒体 / Apple …」以及自定义组;关键是 每个服务组可配置「能使用哪些地区组」(另含直连、拒绝等),这样才是「应用 → 策略组 → 地区节点」这条链。规则
内置预设 + 全量在线规则库(从 MetaCubeX 同步,可搜索,例如搜steam)。注意:全量库是「在工具里浏览和选用 rule-set」,客户端自带的 geo 数据更新仍由各自客户端负责,工具不强行往 YAML 里塞进一整套 geodata-mode(按需保持简单、边界清晰)。正则助手
用「包含 / 排除关键词」生成常见 lookahead 写法,降低地区筛节点名的门槛。工程化能力
项目 JSON 导入导出、本地草稿、中英文界面、发布态还有 Windows 桌面安装包/便携版(GitHub Release)。
四、实现上我坚持的几点
数据要有 Schema(例如 Zod):向导状态和导入的项目要能校验,避免「界面能点、生成出来却是半成品」。
命名组替代写死固定组:以后加场景时扩展字段比硬编码一组组名要轻松。
在线规则列表要「真的能列全」:大仓库用 GitHub API 时要想清楚递归树被截断这类坑(例如只对
geo/子树递归),否则界面里会莫名其妙「一条规则都同步不到」——这也是近期版本里修过的一类问题。
五、适合谁、不适合谁
适合:愿意点向导、说清楚分流意图,希望少碰裸 YAML 的人;需要同时在路由 / PC / 多客户端间统一思路再分别导出的人。
不适合:已经重度魔改内核、完全手写规则链的大佬——他们多半会直接维护仓库里的配置;本工具更偏向「可重复的、可分享的默认范式」。
六、收尾
这个项目的「过程」本质上是:先把问题从「怎么写 YAML」换成「怎么描述分流」,再用一层稳定模型和适配器把描述落地。如果你也在折腾代理分流,希望这篇能帮你判断这类工具是否值得用;若你同在做开源,分层 + 统一模型往往是后期最省时间的决定。
下载链接:下载点我